

Open data has become a mantra for governments and, in many cases, the backbone of commercial and academic projects. In particular, data collected by public bodies in the pursuit of regulatory and legal functions tend to benefit from what we might call ‘assumed validity’: the idea that they must be both ‘correct’ and ‘complete’ because they contain data collected under government mandate for administrative purposes.
The London Datastore, the Office for National Statistics pages, and the Land Registry Price Paid data are just a few examples of this class of data offering, but our experience working with Land Registry data points both to a number of ways in which this default assumption can lead researchers astray and to the kinds of consequences that failing to read the ‘Ts & Cs’ can have for published results. In fact, ‘RTFM’ is really just the first stage in getting to grips with a new data source, and careful testing of record and column integrity will often throw up wild departures from the specification… this blog post covers issues arising from both of these aspects.
About the Price Paid Data Set
It is common to read that the Land Registry’s Price Paid dataset includes all property transactions made in the UK—though technically it’s only England and Wales—and includes basic information such as price, type, and address of the property. However, it is surprisingly common for published research not to clearly engage with the impact of exclusions: Not only are ‘Right to Buy’ transactions excluded, but the status of shared ownership purchases—which could be broadly considered ‘not for value’—is unclear, and in expensive housing markets such as London both these types of transactions can be quite common. Additional exclusions are: non-market transactions, commercial real estate, and property deals involving more than a single home.
In addition, the monthly data feed makes it quite clear that transactions can, and will, be updated / corrected years later. Moreover, the kinds of data published by the Land Registry have evolved over time (e.g. properties purchased by an overseas company), implying that transaction types and attributes included in the data may well change on a publication to publication basis.
Cleaning the Price Paid Data Set
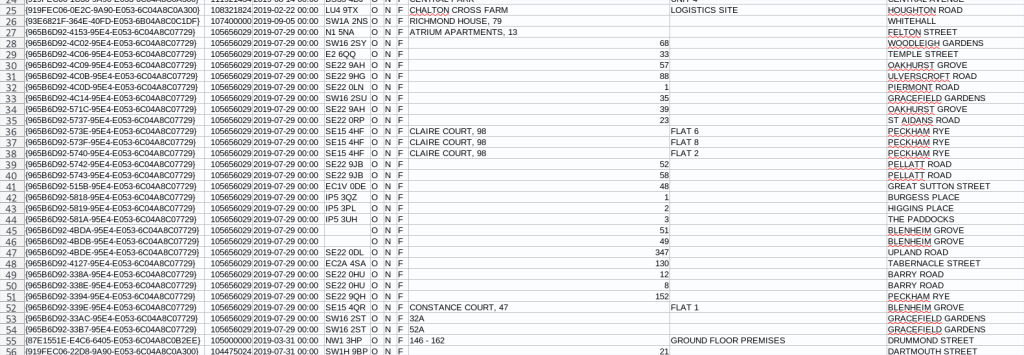
In a recent project using the Price Paid data, I came across two oddities: first, that some prices did not seem to match up with the likely value of the property; and second, that some prices were repeated far more frequently than seemed likely, or even credible. The following examples were taken from the Part 2 2019 Price Paid dataset.
The Most Expensive House in Croydon
On 31 July 2019 someone apparently spent £320 million on a property in London. That is a lot of money and a major sale, but hardly unheard of in the capital of the UK. The oddity arises when looking at the location and size of property sold for this amount: the postcode points to an area of relatively modest single-family homes in the South London borough of Croydon!


I can’t help it, £105,656,029 just feels right
A little further down in the data we find 27 sales for £105 million each. But these aren’t just ‘in the vicinity of’ £105 million each, they are—every single one—for exactly £105,656,029. At the lower end of the PP data set we might expect to see many transactions with similar values because of the overall positive skew in the price distribution, but to find so many transactions in the long tail is, again, simply not credible.
Just Ask
Equipped with these observations, I did something else that can be uncommon for researchers: lodged an enquiry with the Land Registry. The response was quick and to the point: The entries are all faulty and will be removed from the dataset. The rather disturbing issue this raises is that if a quick look through a few hundred records reveals 28 faulty entries, is this a function of the fact that we’re looking at outliers, or evidence of much deeper issues in the robustness of the data?
How would we go about spotting erroneous repeat transactions of £249,999? Or a tiny, run-down property in a prestigious area being erroneously listed as having been bought for £1,250,000 when it should have been £125,000? Given the size of the dataset it is impossible to test every single record, but it points to an important lesson: In the age of machine learning, manual sanity checks of even the most trusted data source should still be the first step in research. Trust, but verify.
